Workshop: Patient Portal, conectando um banco de dados a um cluster K8S com Skupper

Descrição
Este workshop tem como objetivo apresentar o Red Hat Service Interconnect, uma solução de integração de aplicações que permite a comunicação entre diferentes sistemas de forma eficiente e segura.
Arquitetura da Solução
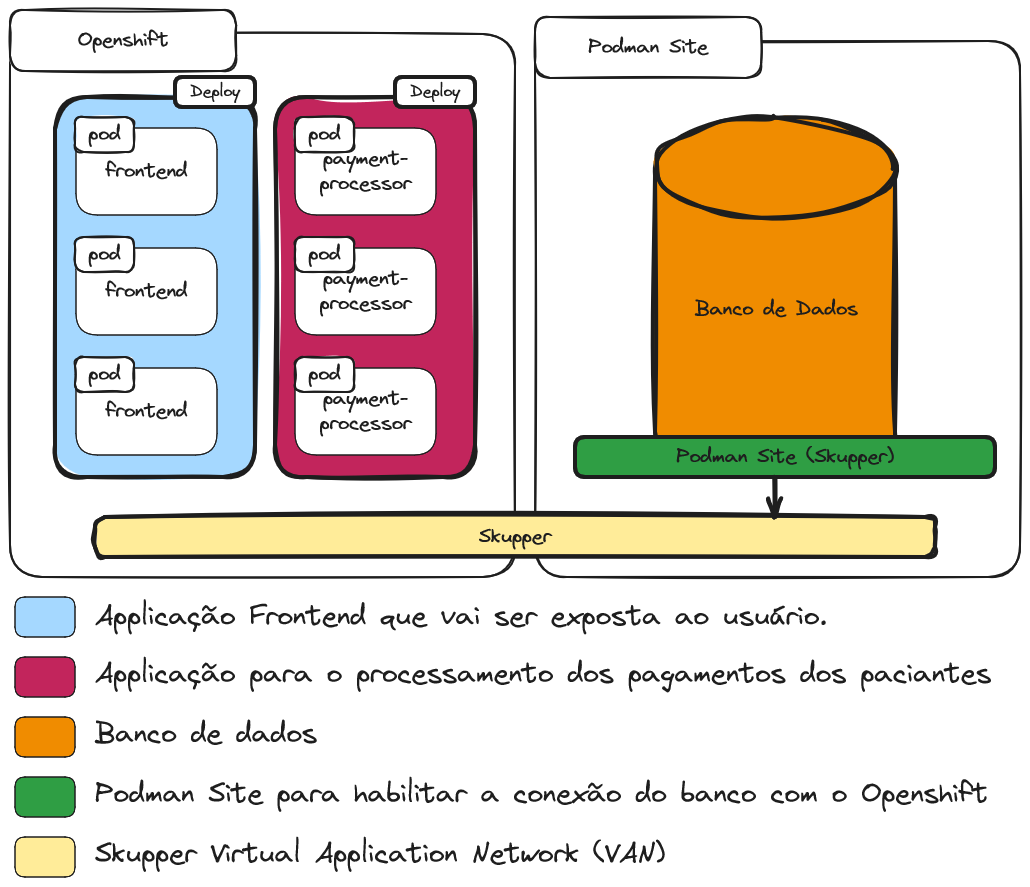
Topologia de Serviços
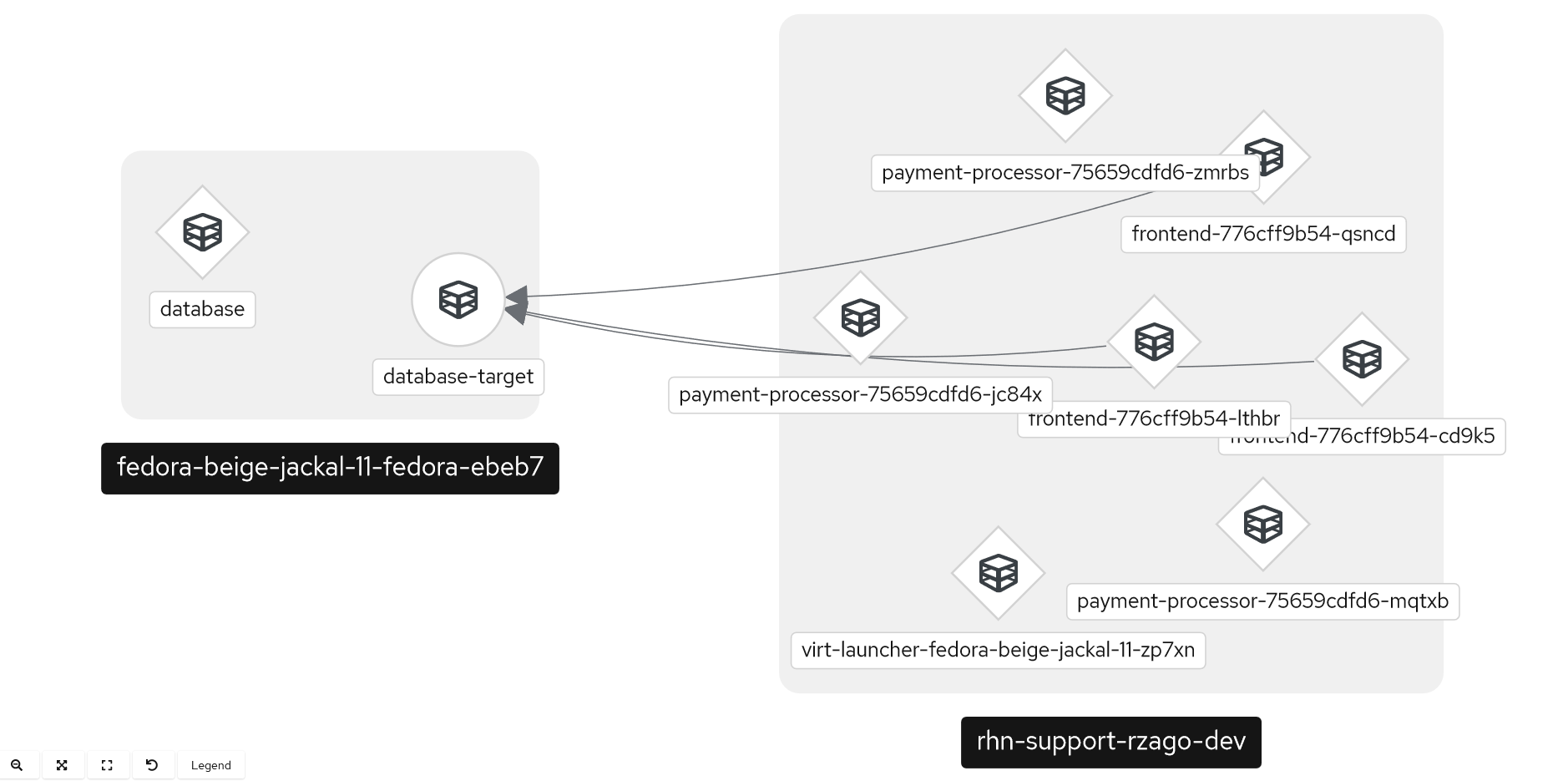
Resumo do Workshop
- Logar no Red Hat Developer.
- Criar um cluster Openshift.
- Acessar o cluster Openshift.
- No projeto do Red Hat Openshift Sandbox, acessar o seu projeto.
- Criar uma máquina virtual no Openshift Virtualization.
- Instalar pacotes na máquina virtual:
- podman
- kubernetes-client
- skupper
- oc
- wget
- Fazer o deploy do banco de dados com o podman.
- Fazer o deploy do frontend e do backend da aplicação.
- Configurar o Service Interconnect (Skupper) para fazer a comunicação do banco de dados rodando em um podman com a aplicação rodando no Openshift.
- Acessar a aplicação e verificar se a comunicação está funcionando.
- Considerações.
Links
| Recurso | Link |
|---|---|
| [1] Red Hat Developer | https://developers.redhat.com/ |
| [2] OC | https://docs.openshift.com/container-platform/4.15/cli_reference/openshift_cli/getting-started-cli.html |
| [3] Skupper | https://skupper.io/ |
Pré-requisitos
- Conta no Red Hat Developer
- Conhecimento básico em Kubernetes
- Conhecimento básico em Red Hat OpenShift
- Conhecimento básico em Podman
- Google Chrome, a preferência por ele é pela funcionalidade de colar comandos no console da máquina virtual pelo VNC via browser.
Passo a passo
1. Logar no Red Hat Developer
Acesse o site do Red Hat Developer e faça o login com a sua conta.
2. Criar um cluster Openshift Sandbox
2.1. Acesse o Red Hat Openshift Sandbox e clique em “Start Cluster”.
2.2. Inicie o cluster Openshift Sandbox.
4. Acessar o cluster Openshift
Acesse o cluster Openshift Sandbox e clique em “Open Console”.
5. No projeto do Red Hat Openshift Sandbox, acessar o seu projeto
Clique no seu projeto e mude para a view “Administrator”.

6. Criar uma máquina virtual no Openshift Virtualization
- Acesse Virtualization no menu do cluster Openshift e clique em Virtual Machines.
- Clique em Create Virtual Machine.
- Escolha From Template e selecione o template Fedora VM.
- Clique em Create VirtualMachine.
7. Instalar pacotes na máquina virtual
- Acesse a máquina virtual e clique em Console. (Dê preferencia para o Google Chrome, pois ele tem a funcionalidade de colar comandos no console da máquina virtual pelo VNC via browser).
- Logue com as credenciais que estão no console.
- Execute os comandos abaixo para instalar os pacotes necessários:
1 2 3 4 5 6
sudo dnf install -y podman kubernetes-client wget # Instalar o oc wget -qO- https://mirror.openshift.com/pub/openshift-v4/clients/ocp/stable/openshift-client-linux.tar.gz | tar xz -C ~/.local/bin export PATH="$HOME/.local/bin:$PATH" # Instalar o skupper curl https://skupper.io/install.sh | sh
8. Fazer o deploy do banco de dados com o podman
Execute o comando abaixo para fazer o deploy do banco de dados:
1
2
podman network create skupper
podman run --name database-target --network skupper --detach --rm -p 5432:5432 quay.io/skupper/patient-portal-database
9. Fazer o deploy do frontend e do backend da aplicação
No seu console openshift, faça o deploy do seguinte yaml para o frontend:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: frontend
name: frontend
spec:
replicas: 3
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: quay.io/skupper/patient-portal-frontend
env:
- name: DATABASE_SERVICE_HOST
value: database
- name: DATABASE_SERVICE_PORT
value: "5432"
- name: PAYMENT_PROCESSOR_SERVICE_HOST
value: payment-processor
- name: PAYMENT_PROCESSOR_SERVICE_PORT
value: "8080"
ports:
- containerPort: 8080
No seu console openshift, faça o deploy do seguinte yaml para o backend:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: payment-processor
name: payment-processor
spec:
replicas: 3
selector:
matchLabels:
app: payment-processor
template:
metadata:
labels:
app: payment-processor
spec:
containers:
- name: payment-processor
image: quay.io/skupper/patient-portal-payment-processor
ports:
- containerPort: 8080
10. Configurar o Service Interconnect (Skupper) para fazer a comunicação do banco de dados rodando em um podman com a aplicação rodando no Openshift.
Para isso, vamos dividir em 3 etapas:
- Configuração do Cluster Kubernetes
- Configuração do Site Podman
- Expor o serviço do banco de dados para a VAN do Skupper
Configuração do Cluster Kubernetes:
- Iniciar o skupper no cluster oenshift com o console habilitado
1
skupper init --enable-console --enable-flow-collector --console-user admin --console-password admin
- Acessar o console do skupper, para isso acesse as rotas do seu cluster Openshift, a URL estará lá.
- Criando um token para conectar o site podman com o cluster Openshift
1
skupper token create ./skupper-token.yaml
Configuração do Site Podman:
- Acesse a máquina virtual e execute o comando abaixo para conectar o site podman com o cluster Openshift
- Ininie o skupper no site podman, sem ingress.
1
skupper switch podman # para mudar o contexto para podman o padrão é kubernetes - Conecte o site podman com o cluster Openshift
1
skupper link create ./skupper-token.yamlAcesse o console do skupper no cluster Openshift e verifique se o site podman está conectado.
Expor o serviço do banco de dados para a VAN do Skupper:
- Expor o serviço do banco de dados para a VAN do Skupper
1 2 3
systemctl --user enable --now podman.socket skupper service create database 5432 skupper service bind database host database-target --target-port 5432
- No cluster Openshift, vamos criar um serviço Skupper para o banco de dados, esse serviço vai apontar para o serviço do banco de dados que está rodando no site podman, através da VAN do Skupper.
1
skupper service create database 5432
Agora, a aplicação frontend e backend estão se comunicando com o banco de dados que está rodando em um site podman, através da VAN do Skupper.
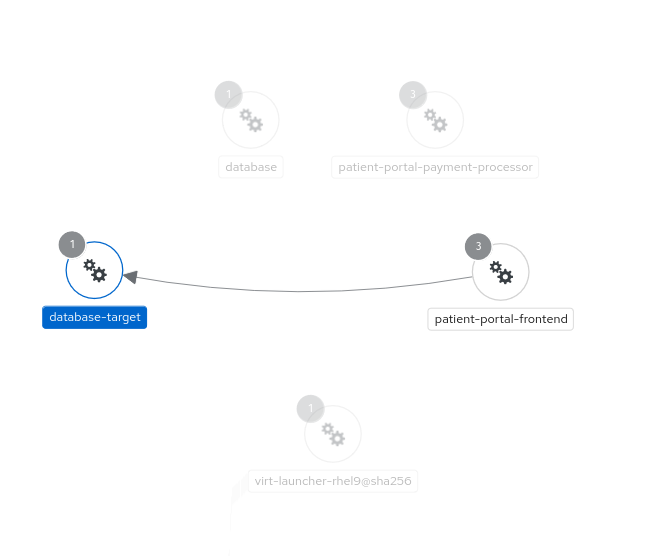
13. Acessar a aplicação e verificar se a comunicação está funcionando
Para isso, vamos precisar executar algumas tarefas para expor o frontend no cluster Openshift.
Criar um serviço para o fronend que aponte para o deployment dele use o seguinte YAML:
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Service
metadata:
name: frontend
namespace: SEU-NAME-SPACE
spec:
selector:
app: frontend
ports:
- protocol: TCP
port: 8080
targetPort: 8080
Criar uma rota que aponte para o serviço do frontend.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: frontend
namespace: SEU-NAME-SPACE
labels: {}
spec:
to:
kind: Service
name: frontend
tls: {}
port:
targetPort: 8080
alternateBackends: []
14. Considerações
O Red Hat Service Interconnect (Skupper):
Oferece uma solução poderosa para integrar aplicações em diferentes ambientes, simplificando a comunicação entre serviços e proporcionando maior flexibilidade e escalabilidade. Ao abstrair a complexidade da rede subjacente, o Skupper permite que os desenvolvedores se concentrem na lógica de negócios de suas aplicações, sem se preocupar com os detalhes de conectividade.
Com recursos como descoberta de serviços automática:
O roteamento inteligente e segurança integrada, o Skupper garante que as aplicações possam se comunicar de forma eficiente e segura, independentemente de sua localização. Essa abordagem simplifica a gestão da infraestrutura e reduz a necessidade de configurações manuais, agilizando o desenvolvimento e a implantação de aplicações distribuídas.
Além disso, o Skupper oferece uma interface de usuário intuitiva e ferramentas de linha de comando poderosas, facilitando a configuração e o monitoramento da comunicação entre serviços. Com sua arquitetura extensível e suporte a diversos protocolos, o Skupper se adapta a diferentes cenários de integração, atendendo às necessidades de projetos de todos os portes.
Resumo
Neste workshop, você aprendeu como usar o Red Hat Service Interconnect (Skupper) para conectar um banco de dados a um cluster Kubernetes, permitindo que aplicações distribuídas se comuniquem de forma eficiente e segura. Com o Skupper, você pode simplificar a integração de serviços em ambientes heterogêneos, facilitando o desenvolvimento e a implantação de aplicações modernas. Esperamos que este workshop tenha sido útil e que você possa aplicar esses conhecimentos em seus próprios projetos. Obrigado por participar!